
RESEARCH
This page briefly describes his research work and subject interests.
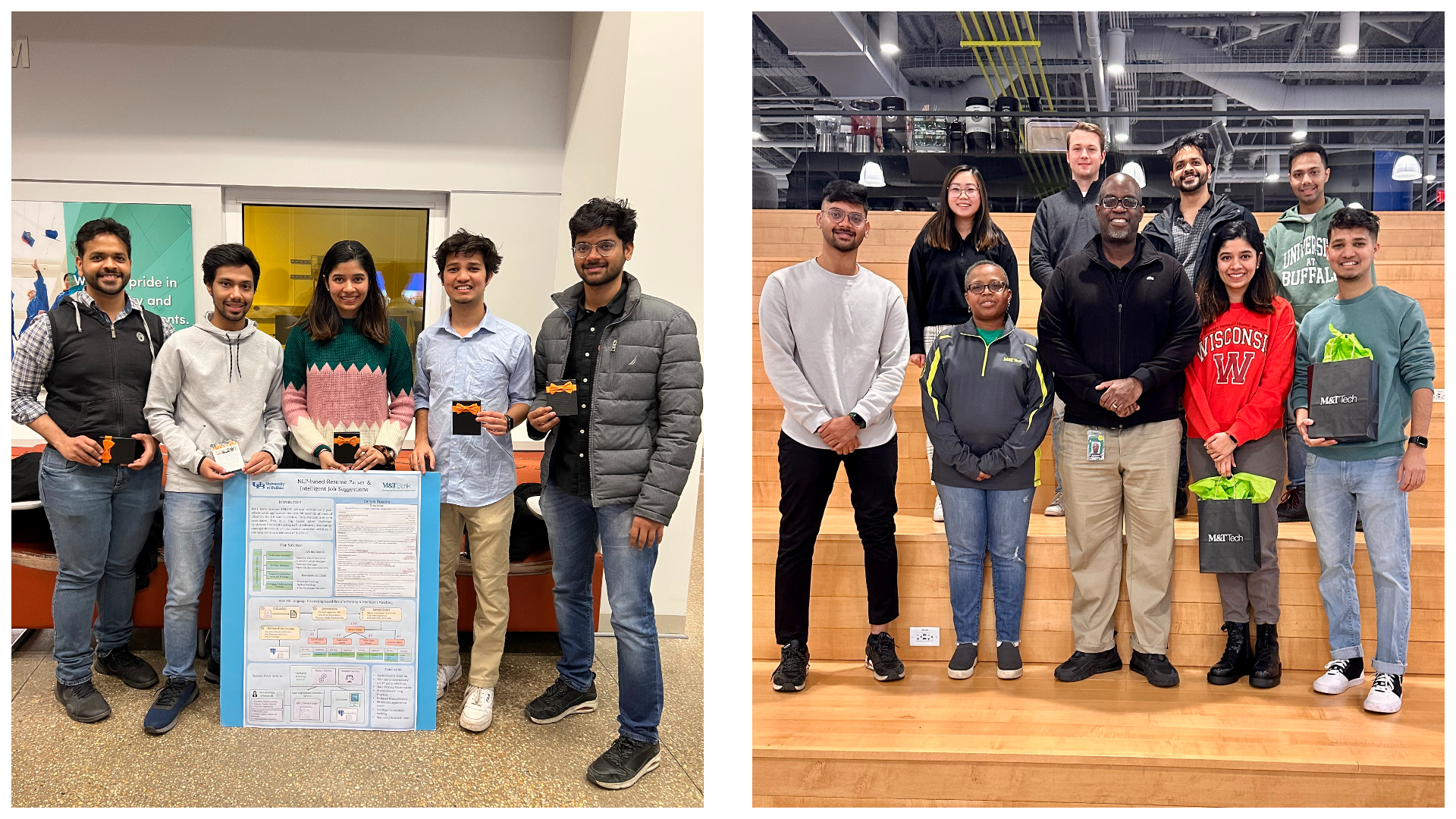
NLP-based Resume Parsing and Intelligent Job Recommendations
[Aug 2022 - Dec 2022]
This project was developed as a collaboration between M&T Bank and the University at Buffalo with a vision to develop an intelligent, customizable, in-house solution for smart recruitment. The product was an end-to-end solution supported with NLP/ML-based algorithms for parsing, matching, and ranking resumes. The entire Web Application was built on Java/Springboot with the look and feel of ReactJs. The solution was deployed and hosted on IBM Cloud powered by XLAB@UB.
Awards: 1st Prize at the Fall 2022 CSE Demo Day
Project Advisees
University at Buffalo - Prof. Jinjun Xiong, Amir Nassereldine
M&T Bank Tech: Murray Richburg, Romunda (Harris) Harris-Fonville
Science of Science
[2021 - 2022]
Science of Science is an emerging interdisciplinary research area that aims to understand the overall structure and functioning of scientific advancement. Although popularly quoted as “Science of Science”, this field falls under the hood of “Meta-science or Meta-research”, which further comes under the larger hood of “Logology”. Logology or Metascience is the use of scientific methods to understand science activities like publishing papers, patents, funding impact, author influence, collaborations, etc.
This research project was advised by Prof. Jinjun Xiong at X-LAB @ UB.
Some of the questions he tried to examine:
- How can we use scientific concepts like Knowledge Graphs, Graph Analytics, Citation Analysis, Scientometrics, and Bibliometrics to study the scientific enterprise itself?
- How do we identify the underlying patterns and rules governing the science system?
- How do we understand & quantify scientific innovation and predict new research directions to advance the scientific enterprise?
- How do we quantify diversity and interdisciplinary related metrics for articles, authors, and academic institutions in general?

Event Prediction from Unstructured Text Data
[2019 - 2020]
An event is generally defined as an incident that happens at a certain time and place and may or may not attract people’s attention. Event Detection is a well-researched field, however, utilizing unstructured text data for predicting events (or event features) was a fairly new research direction in early 2019.
This project was sponsored by the Applied AI Group of C-DAC - an R&D Society operating under the Government of India. This research was advised by Dr. Krishnanjan Bhattacharjee.
Some of the questions he tried to examine:
- How do we model unstructured text data as a knowledge graph to predict potential crime/terrorism events?
- How to extract linguistic markers and pre-event indicators (semantic triples) using NLP tasks like Entity Disambiguation, Entity Resolution, and Dependency Parsing?
- How do we build a weighted rule-based algorithm for predicting future links between nodes of the knowledge graph?
Political Discourse Analytics
[2018 - 2019]
Political Discourse Analytics is an approach to understanding the nature and function of world-level to root-level political discourse using digital data sources like speech transcripts, debates, published articles, blogs, tweets, and other forms of documentation to derive automated political inferences, conclusions, predicting political impact, etc. He is specifically interested in conducting the discourse studies using NLP approaches like text analytics, topic discovery/topic modeling, semantic analysis, text embedding technologies to better understand political language, etc.
Some of the questions he tried to examine:
- How do we use language technologies to trace and identify socio-political issues from political speech transcripts?
- How do we extract and interpret latent political ideologies, topics/shades from large unstructured corpora?
- How can a study like this be made useful for political analysts, political party strategists, and the people to assess multiple political candidates and their political attitudes & discourse?